Cuộc đua Googlebot là một giải đấu bất thường được theo dõi hàng ngày với sự tham gia của hơn 1,8 tỷ trang web. Giải đấu bao gồm nhiều cuộc thi thường được gọi là các yếu tố xếp hạng của Hồi. Mỗi năm, ai đó cố gắng mô tả càng nhiều trong số họ càng tốt, nhưng không ai thực sự biết tất cả những gì về họ và có bao nhiêu. Không ai ngoài Googlebot. Chính anh ta là người hàng ngày vượt qua hàng petabyte dữ liệu, buộc các quản trị web phải cạnh tranh trên các lĩnh vực kỳ lạ nhất, để chọn ra những dữ liệu tốt nhất. Hoặc đó là những gì anh ấy nghĩ.
Chạy 1.000 mét (với dốc đứng) - chúng tôi đang kiểm tra tốc độ lập chỉ mục. Đối với cuộc thi này, tôi đã trình bày năm cấu trúc dữ liệu tương tự. Mỗi người trong số họ có 1000 trang con với nội dung độc đáo và các trang điều hướng bổ sung (ví dụ: các trang phụ hoặc danh mục khác). Dưới đây bạn có thể thấy kết quả cho bốn bài hát đang chạy.
Cấu trúc dữ liệu này rất kém với 1.000 liên kết đến các trang con có nội dung duy nhất trên một trang (vì vậy 1.000 liên kết nội bộ). Tất cả các chuyên gia SEO (bao gồm cả tôi) lặp lại nó như một câu thần chú: không quá 100 liên kết nội bộ trên mỗi trang hoặc Google sẽ không quản lý để thu thập dữ liệu một trang rộng rãi như vậy và nó sẽ chỉ bỏ qua một số liên kết và nó sẽ không lập chỉ mục cho chúng. Tôi quyết định xem nó có đúng không.

Đây là một đường chạy trung bình. 100 trang con khác (trên mỗi trang, có thể nhìn thấy các liên kết đến một vài trang trước, một vài trang tiếp theo, đến trang đầu tiên và trang cuối cùng). Trên mỗi trang con, 10 liên kết nội bộ đến các trang có nội dung. Trang đầu tiên bao gồm chỉ mục / theo dõi thẻ meta robot, trang còn lại noindex / follow.

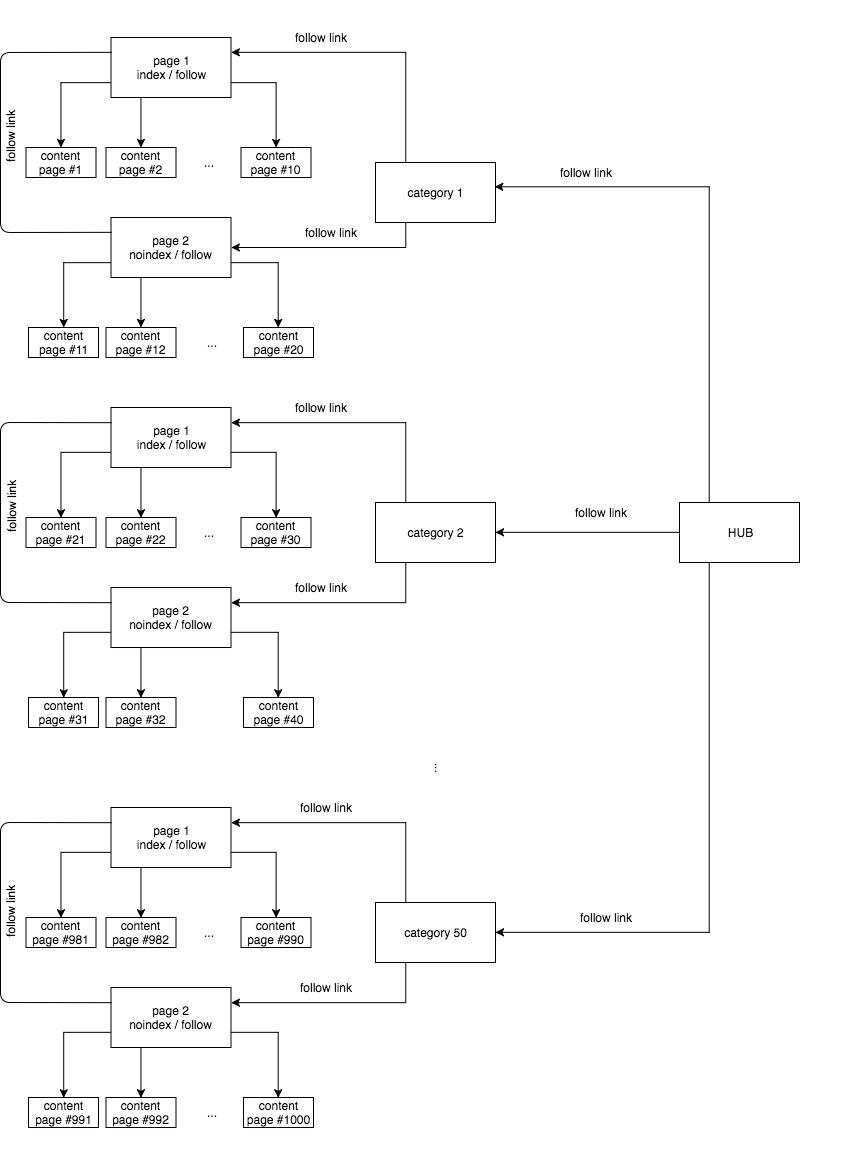
Tôi muốn giới thiệu một chút nhầm lẫn, vì vậy tôi quyết định tạo cấu trúc silo trên trang web và tôi chia nó thành 50 loại. Trong mỗi trang, có 20 liên kết đến các trang nội dung được chia thành hai trang.
Đường chạy tiếp theo là con ngựa đen của giải đấu này. Không phân trang / phân trang bình thường. Thay vào đó, chỉ dựa vào = = tiếp theo, tôi dựa vào tiêu đề phân trang / phân trang, xác định trang sau mà Googlebot sẽ đi.

Chạy theo dõi số hai là tương tự. Sự khác biệt là tôi đã thoát khỏi index / noindex và tôi đặt các thẻ chuẩn cho tất cả các trang con vào trang đầu tiên.

và họ đã chiếm được

lượt truy cập - tổng số lượt truy cập Googlebot được lập chỉ mục - số lượng trang được lập chỉ mục
Tôi phải thừa nhận rằng tôi đã thất vọng về kết quả. Tôi đã rất hy vọng chứng minh rằng cấu trúc silo sẽ tăng tốc độ thu thập dữ liệu và lập chỉ mục của trang web. Thật không may, nó đã không xảy ra. Kiểu cấu trúc này là cấu trúc mà tôi thường đề xuất và triển khai trên các trang web mà tôi quản lý, chủ yếu là do các khả năng mà nó mang lại cho liên kết nội bộ. Đáng buồn thay, với một lượng thông tin lớn hơn, nó không đi đôi với tốc độ lập chỉ mục.
Tuy nhiên, thật ngạc nhiên, Googlebot dễ dàng xử lý việc đọc 1.000 liên kết nội bộ, truy cập chúng trong 30 ngày và lập chỉ mục đa số. Nhưng người ta thường tin rằng số lượng liên kết nội bộ nên là 100 trên mỗi trang. Điều này có nghĩa là nếu chúng tôi muốn tăng tốc độ lập chỉ mục, chúng tôi nên tạo bản đồ của trang web ở định dạng HTML ngay cả với số lượng liên kết lớn như vậy.
Đồng thời, lập chỉ mục cổ điển với noindex / follow hoàn toàn thua cuộc khi phân trang với việc sử dụng index / follow và rel = canonical directing đến trang đầu tiên. Trong trường hợp cuối cùng, Googlebot dự kiến sẽ không lập chỉ mục các trang con được phân trang cụ thể. Tuy nhiên, từ 100 trang con được phân trang, nó đã được lập chỉ mục năm, mặc dù thẻ chính tắc đến trang một, hiển thị lại rằng việc đặt các thẻ chính tắc không đảm bảo tránh việc lập chỉ mục của trang và kết quả lộn xộn trong tìm kiếm chỉ số động cơ.
Trong trường hợp thử nghiệm được mô tả ở trên, công trình cuối cùng là công trình hiệu quả nhất cho số lượng trang được lập chỉ mục. Nếu chúng tôi giới thiệu Tỷ lệ chỉ mục khái niệm mới được xác định bằng tỷ lệ số lượt truy cập Googlebot với số trang được lập chỉ mục, ví dụ: trong vòng 30 ngày, thì IR tốt nhất trong thử nghiệm của chúng tôi sẽ là 3,89 (chạy theo dõi 5) và tồi tệ nhất sẽ là 6,46 (chạy track 2). Con số này sẽ đại diện cho số lượt truy cập trung bình của Googlebot trên một trang được yêu cầu để lập chỉ mục cho nó (và giữ nó trong chỉ mục). Để xác định thêm IR, sẽ đáng để xác minh việc lập chỉ mục hàng ngày cho một URL cụ thể. Sau đó, nó chắc chắn sẽ có ý nghĩa hơn.
Một trong những kết luận chính từ bài viết này (sau vài ngày kể từ khi bắt đầu thử nghiệm) sẽ chứng minh rằng Googlebot bỏ qua các thẻ rel = next và rel = trước. Thật không may, tôi đã trễ công bố những kết quả đó (chờ thêm) và John Muller vào ngày 21 tháng 3 đã thông báo với thế giới rằng thực sự, những thẻ này không được Googlebot sử dụng. Tôi chỉ tự hỏi liệu thực tế là tôi đang gõ bài viết này trong Google Docs có liên quan gì đến nó không (#conspiracytheory).
Rất đáng để xem các trang có chứa cuộn vô hạn - tải lên nội dung động, tải lên sau khi cuộn xuống phần dưới của trang và điều hướng dựa trên rel = trước và rel = tiếp theo. Nếu không có điều hướng nào khác, chẳng hạn như phân trang thông thường ẩn trong CSS (vô hình cho người dùng nhưng hiển thị cho Googlebot), chúng tôi có thể chắc chắn rằng quyền truy cập của Googlebot vào nội dung mới được tải lên (sản phẩm, bài viết, ảnh) sẽ bị cản trở.